





















 1,672
1,672¡Hola a todos! ¡Estamos de vuelta en el negocio!
Después de un período muy largo, finalmente hemos preparado una nueva versión de SiteAnalyzer, que, esperamos, cumpla con sus expectativas y se convierta en un asistente indispensable en la promoción de SEO.
En la nueva versión de SiteAnalyzer, hemos implementado varias de las funciones más solicitadas por los usuarios, tales como: raspado de datos (extracción de datos del sitio), verificación de la unicidad del contenido y verificación de la velocidad de carga de la página mediante Google PageSpeed. Al mismo tiempo, se corrigieron muchos errores y se rediseñó el logotipo. Hablemos de todo con más detalle.

Los principales cambios
1. Extracción de datos con XPath, CSS, XQuery, RegEx.
El web scraping es un proceso automatizado de extracción de datos de las páginas de interés en el sitio de acuerdo con ciertas reglas.
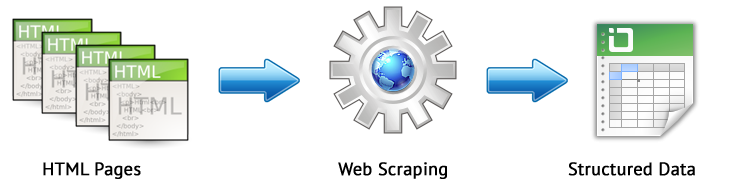
Los principales métodos de raspado web son los métodos de análisis que utilizan XPath, selectores CSS, XQuery, RegExp y plantillas HTML.
- XPath es un lenguaje de consulta especial para elementos de documentos XML / XHTML. Para acceder a los elementos, XPath utiliza la navegación DOM al describir la ruta al elemento deseado en la página. Con su ayuda, puede obtener el valor de un elemento por su número ordinal en el documento, extraer su contenido de texto o código interno, verificar la presencia de un elemento específico en la página.
- Los selectores CSS se utilizan para encontrar un elemento de su parte (atributo). CSS es sintácticamente similar a XPath, pero en algunos casos los localizadores CSS son más rápidos y más descriptivos y concisos. La desventaja de CSS es que solo funciona en una dirección: más profundamente en el documento. XPath, por otro lado, funciona en ambos sentidos (por ejemplo, puede buscar un elemento principal por un elemento secundario).
- XQuery se basa en XPath. XQuery imita XML, lo que le permite crear expresiones anidadas de una manera que no es posible en XSLT.
- RegExp es un lenguaje de búsqueda formal para extraer valores de un conjunto de cadenas de texto que cumplen las condiciones requeridas (expresión regular).
- Las plantillas HTML es un lenguaje para extraer datos de documentos HTML, que es una combinación de marcado HTML para describir la plantilla de búsqueda para el fragmento deseado, además de funciones y operaciones para extraer y transformar datos.
Por lo general, el raspado se usa para resolver tareas que son difíciles de manejar manualmente. Esto puede ser extraer descripciones de productos para crear una nueva tienda en línea, realizar investigaciones de mercado para monitorear precios o monitorear anuncios.

En SiteAnalyzer, el raspado se configura en la pestaña Extracción de datos, donde se configuran las reglas de extracción. Las reglas se pueden guardar y, si es necesario, editar.
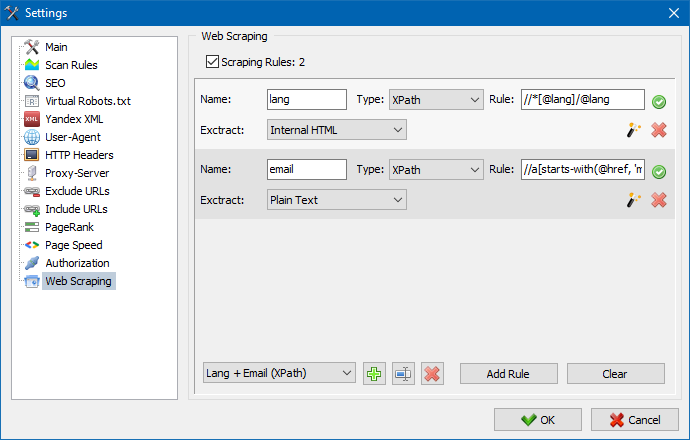
También hay un módulo de prueba de reglas. Con el depurador de reglas incorporado, puede obtener rápida y fácilmente el contenido HTML de cualquier página del sitio y probar el trabajo de las consultas, y luego usar las reglas depuradas para analizar datos en SiteAnalyzer.

Una vez finalizada la extracción de datos, toda la información recopilada se puede exportar a Excel.
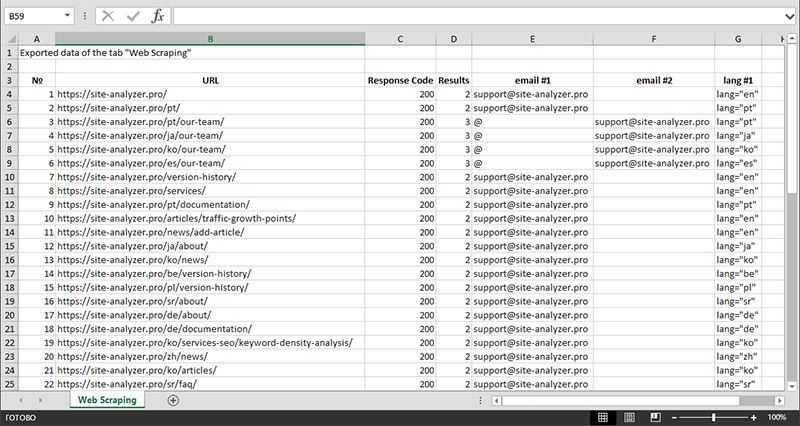
Para un estudio más detallado del funcionamiento del módulo y una lista de las reglas y expresiones regulares más comunes, consulte el artículo
2. Comprobación de la singularidad del contenido dentro del sitio.
Esta herramienta le permite buscar páginas duplicadas y verificar la singularidad de los textos dentro del sitio. En otras palabras, se trata de una verificación por lotes de un grupo de URL para determinar la unicidad entre ellas.
Esto puede resultar útil en los siguientes casos:
- Para buscar páginas completas duplicadas (por ejemplo, una página con parámetros y la misma página, pero en la vista CNC).
- Para buscar coincidencias de contenido parcial (por ejemplo, dos recetas de borscht en un blog culinario, que son 96% similares entre sí, lo que sugiere que uno de los artículos debe eliminarse para deshacerse de una posible canibalización del tráfico).
- Cuando en un sitio de artículos, accidentalmente escribiste un artículo sobre un tema que ya escribiste hace 10 años. En este caso, nuestra herramienta también detectará un duplicado de dicho artículo.
El principio de la herramienta para verificar la unicidad del contenido es simple: el programa descarga su contenido de la lista de URL del sitio web, recibe el contenido de texto de la página (sin el bloque HEAD y sin etiquetas HTML) y luego los compara con cada otros utilizando el algoritmo de tejas.

Por lo tanto, mediante el uso de tejas, determinamos la singularidad de las páginas y podemos calcular tanto los duplicados completos de páginas con un 0% de singularidad como los duplicados parciales con varios grados de singularidad del contenido del texto. El programa funciona con una longitud de teja de 5.
Puede obtener más información sobre cómo funciona el módulo en este artículo.: >>
3. Comprobación de la velocidad de carga de las páginas mediante Google PageSpeed.
La herramienta PageSpeed Insights del gigante de las búsquedas de Google le permite verificar la velocidad de carga de ciertos elementos de la página y también muestra el puntaje general de velocidad de carga de las URL de interés para las versiones de escritorio y móviles del navegador.

La herramienta de Google es buena para todos, sin embargo, tiene un inconveniente significativo: no le permite crear verificaciones grupales de URL, lo que crea inconvenientes al verificar muchas páginas de su sitio: acuerde que verificar manualmente la velocidad de descarga para 100 o más URL en una página es una tarea ardua y puede llevar mucho tiempo.
Por lo tanto, hemos creado un módulo que le permite crear verificaciones grupales de la velocidad de carga de la página de forma gratuita a través de una API especial en la herramienta Google PageSpeed Insights.

Principales parámetros analizados:
- FCP (First Contentful Paint) – tiempo para mostrar el primer contenido.
- SI (Speed Index) – un indicador de la rapidez con que se muestra el contenido en una página.
- LCP (Largest Contentful Paint) – tiempo de visualización del elemento más grande de la página.
- TTI (Time to Interactive) – el tiempo durante el cual la página está completamente lista para la interacción del usuario.
- TBT (Total Blocking Time) – tiempo desde la primera reproducción del contenido hasta su preparación para la interacción del usuario.
- CLS (Cumulative Layout Shift) – cambio de diseño acumulativo. Sirve para medir la estabilidad visual de la página.
Debido al trabajo de múltiples subprocesos de SiteAnalyzer, la verificación de cientos o más URL puede llevar solo unos minutos, lo que podría llevar un día o más en modo manual a través de un navegador.
Al mismo tiempo, el análisis de la propia URL se lleva a cabo con solo un par de clics, después de lo cual se puede descargar un informe, que incluye las principales características de los cheques en un formato conveniente en Excel.
Todo lo que necesita para comenzar es obtener una clave API.
En este artículo se describe cómo hacer esto. >>
4. Se agregó la capacidad de agrupar proyectos por carpetas.
Para una navegación más conveniente a través de la lista de proyectos, se ha agregado la capacidad de agrupar sitios por carpetas.

Además, fue posible filtrar la lista de proyectos por nombre.
5. La interfaz de la configuración del programa se ha actualizado.
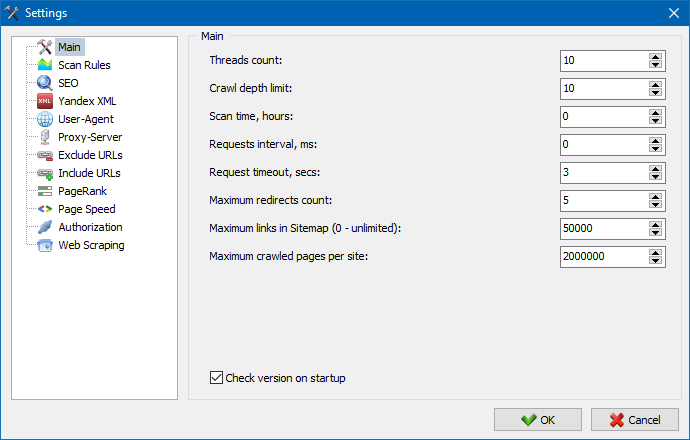
Con la expansión de la funcionalidad del programa, se volvió "ajustado" para nosotros el uso de pestañas, por lo que reformateamos la ventana de configuración en una interfaz más comprensible y funcional.
Notas:
- se corrigió la contabilidad incorrecta de las excepciones de URL.
- se corrigió la contabilidad incorrecta de la profundidad de rastreo del sitio.
- visualización restaurada de redirecciones para URL importadas desde un archivo
- restauró la capacidad de reorganizar y recordar el orden de las columnas en las pestañas
- restauró la contabilidad de páginas no canónicas, resolvió el problema con metaetiquetas vacías
- visualización restaurada de anclajes de enlace en la pestaña Información
- importación acelerada de una gran cantidad de URL desde el portapapeles
- se corrigió el análisis no siempre correcto del título y la descripción.
- visualización restaurada de alt y título en imágenes
- congelación fija al cambiar a la pestaña "Enlaces externos" mientras se escanea un proyecto
- se corrigió el error que ocurría al cambiar entre proyectos y actualizar los nodos de la pestaña "Estadísticas de rastreo del sitio".
- se corrigió la definición incorrecta del nivel de anidamiento para URL con parámetros.
- clasificación de datos fija por campo HTML-hash en la tabla principal
- trabajo optimizado del programa con dominios cirílicos
- interfaz de configuración del programa actualizada
- diseño de logotipo actualizado


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Resumen de versiones anteriores:
- Introducción a la nueva versión SiteAnalyzer 2.2
- Introducción a la nueva versión SiteAnalyzer 2.1
- Introducción a la nueva versión SiteAnalyzer 2.0


















